Academic Research
Gaze Typing in Virtual Reality: Impact of Keyboard Design, Selection Method, and Motion

Our findings suggest that 1) gaze typing in VR is viable but constrained, 2) the users perform best (10.15 WPM) when the entire keyboard is within-view; the larger-than-view keyboard (9.15 WPM) induces physical strain due to increased head movements, 3) motion in the field of view impacts the user's performance: users perform better while stationary than when in motion, and 4) gaze+click is better than dwell only (fixed at 550 ms) interaction.
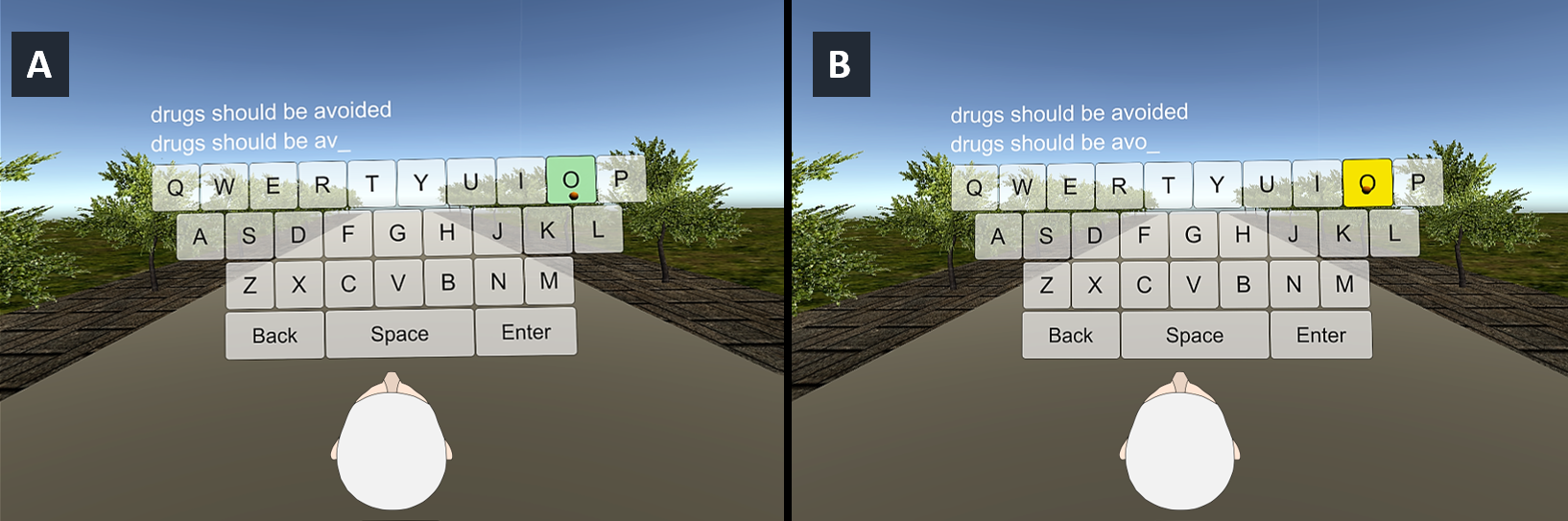

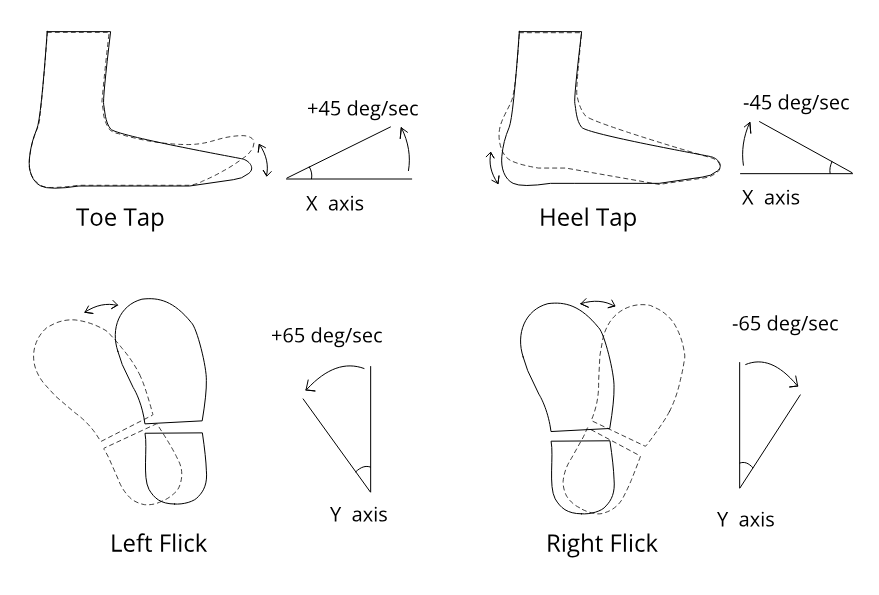
PressTapFlick: Exploring a Gaze and Foot-based Multimodal Approach to Gaze Typing


Text entry is extremely difficult or sometimes impossible in the scenarios of situationally-induced or physical impairments and disabilities. As a remedy, many rely on gaze typing which commonly uses dwell time as the selection method. However, dwell-based gaze typing could be limited by usability issues, reduced typing speed, high error rate, steep learning curve, and visual fatigue with prolonged usage. We present a dwell-free, multimodal approach to gaze typing where the gaze input is supplemented with a foot input modality. In this multi-modal setup, the user points her gaze at the desired character, and selects it with the foot input. We further investigated two approaches to foot-based selection, a foot gesture-based selection and a foot press-based selection, which are compared against the dwell-based selection.
We evaluated our system through three experiments involving 51 participants, where each experiment used one of the three target selection methods: dwell-based, foot gesture-based, and foot press-based selection. We found that foot-based selection at least matches, and likely improves, the gaze typing performance compared to dwell-based selection. Among the four foot gestures (toe tapping, heel tapping, right flick and left flick) we used in the study, toe tapping is the most preferred gesture for gaze typing. Furthermore, when using foot-based activation users quickly develop a rhythm in focusing at a character with gaze and selecting it with the foot. This familiarity reduces errors significantly. Overall, based on both typing performance and qualitative feedback the results suggest that gaze and foot-based tying is convenient, easy to learn, and addresses the usability issues associated with dwell-based typing. We believe, our findings would encourage further research in leveraging a supplemental foot input in gaze typing, or in general, would assist in the development of rich foot-based interactions.
Can Gaze Beat Touch? A Fitts' Law Evaluation of Gaze, Touch, and Mouse Inputs


Gaze input has been a promising substitute for mouse input for point and select interactions. Individuals with severe motor and speech disabilities primarily rely on gaze input for communication. Gaze input also serves as a hands-free input modality in the scenarios of situationally-induced impairments and disabilities (SIIDs). Hence, the performance of gaze input has often been compared to mouse input through standardized performance evaluation procedure like the Fitts' Law. With the proliferation of touch-enabled devices such as smartphones, tablet PCs, or any computing device with a touch surface, it is also important to compare the performance of gaze input to touch input.
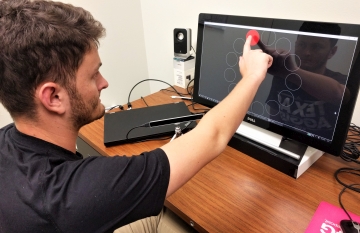
In this study, we conducted ISO 9241-9 Fitts' Law evaluation to compare the performance of multimodal gaze and foot-based input to touch input in a standard desktop environment, while using mouse input as the baseline. From a study involving 12 participants, we found that the gaze input has the lowest throughput (2.55 bits/s), and the highest movement time (1.04 s) of the three inputs. In addition, though touch input involves maximum physical movements, it achieved the highest throughput (6.67 bits/s), the least movement time (0.5 s), and was the most preferred input. While there are similarities in how quickly pointing can be moved from source to target location when using both gaze and touch inputs, target selection consumes maximum time with gaze input. Hence, with a throughput that is over 160% higher than gaze, touch proves to be a superior input modality.
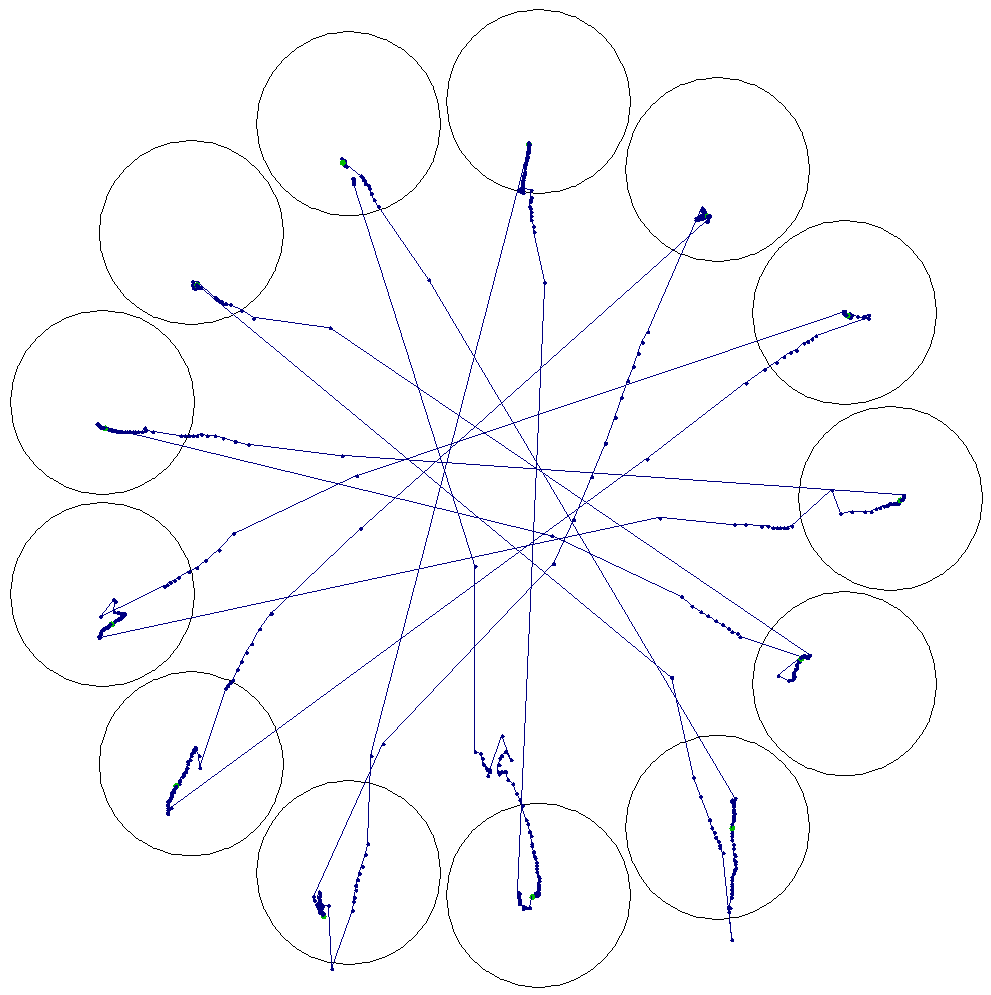
A Fitts' Law Evaluation of Gaze Input on Large Displays Compared to Touch and Mouse Inputs
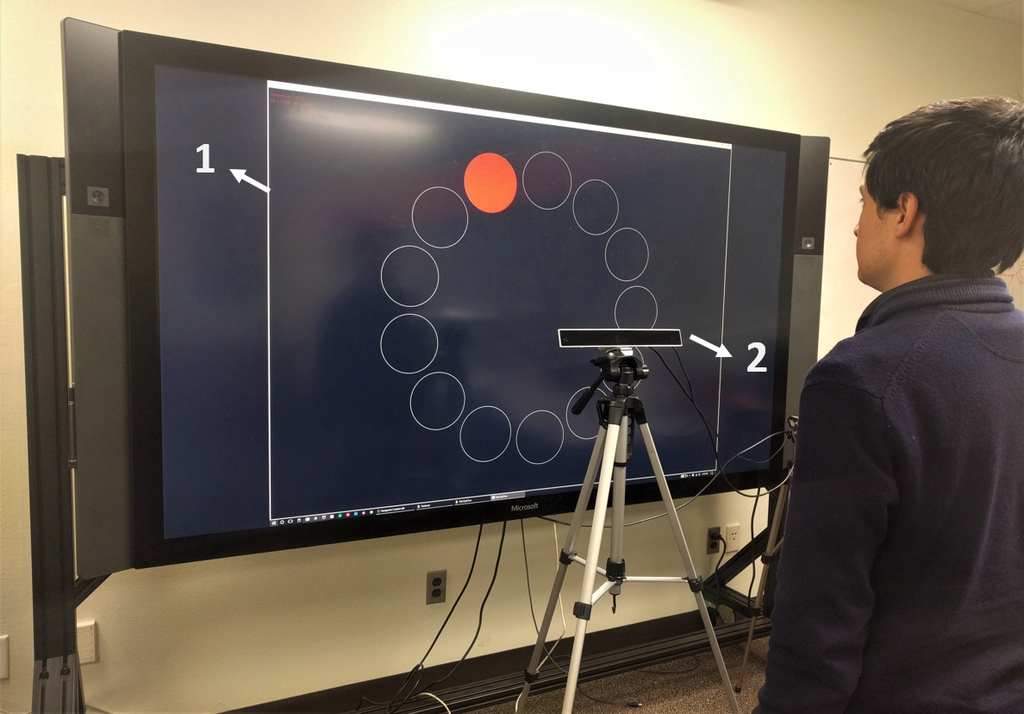


A Gaze Gesture-Based Paradigm for Situational Impairments, Accessibility, and Rich Interactions

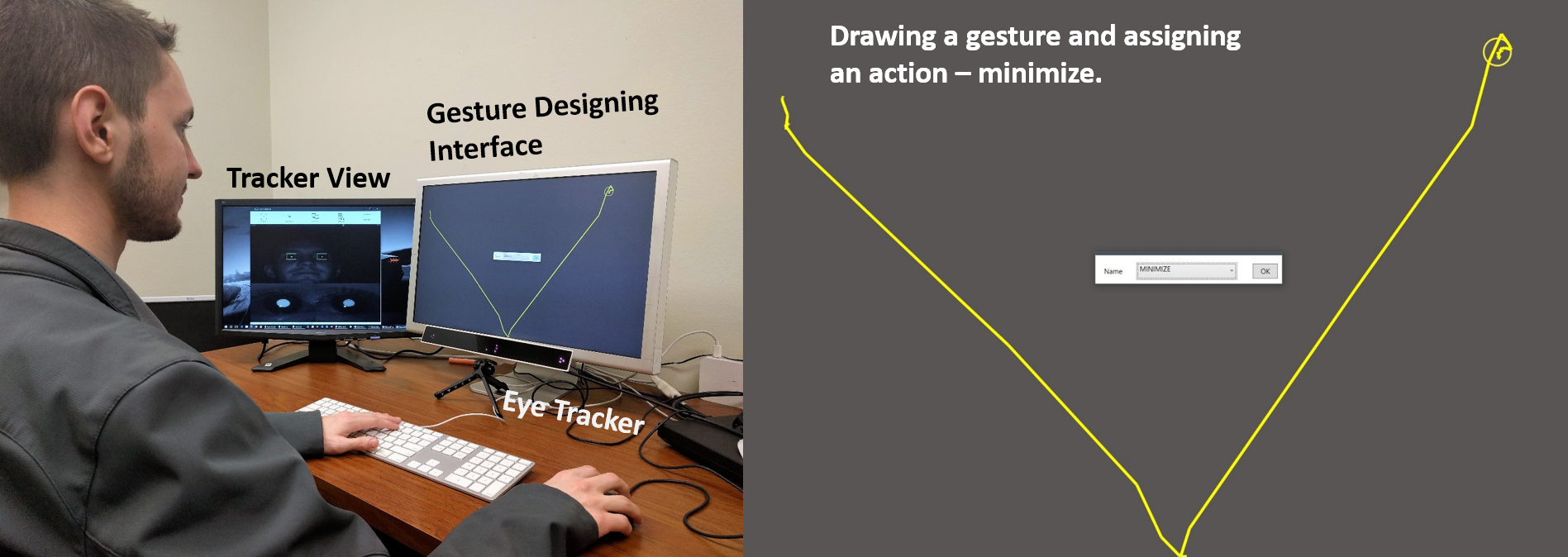
DyGazePass: A Gaze Gesture-Based Dynamic Authentication System to Counter Shoulder Surfing Attacks

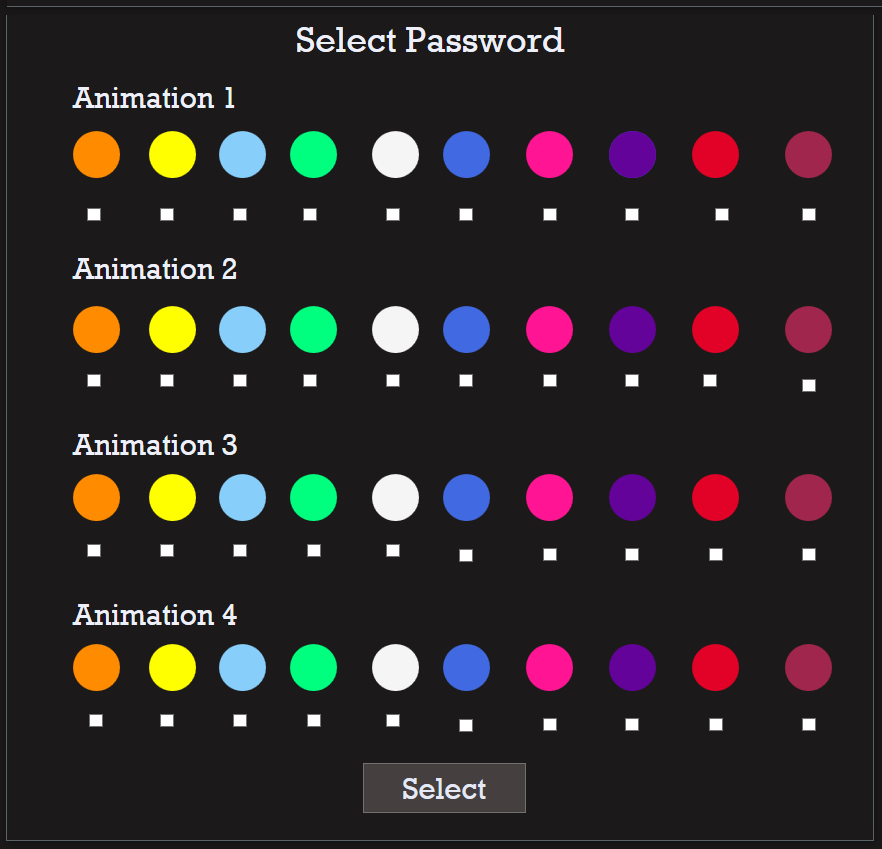

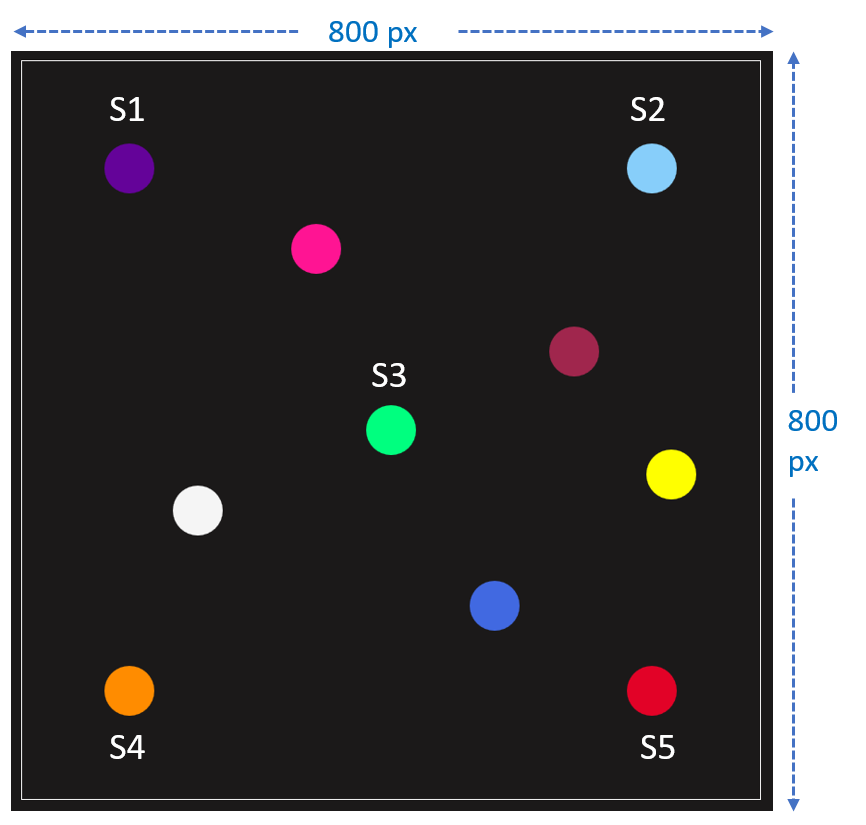
A Gaze Gesture-Based User Authentication System to Counter Shoulder-Surfing Attacks




Gaze Gesture-Based Interactions for Accessible HCI

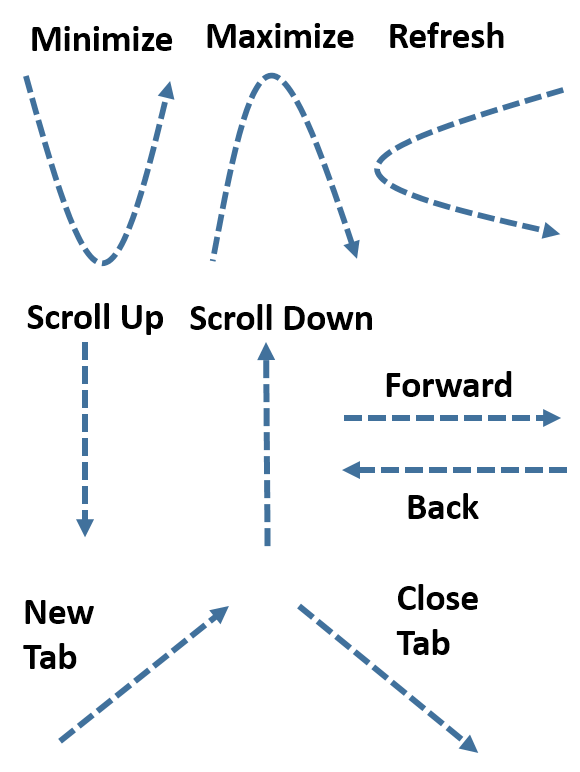
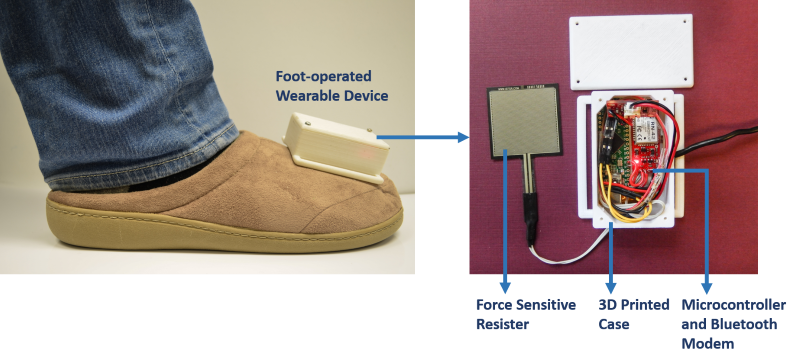
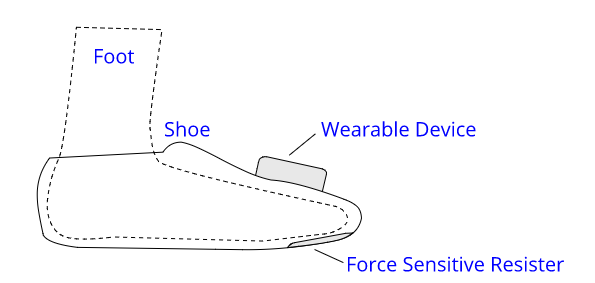
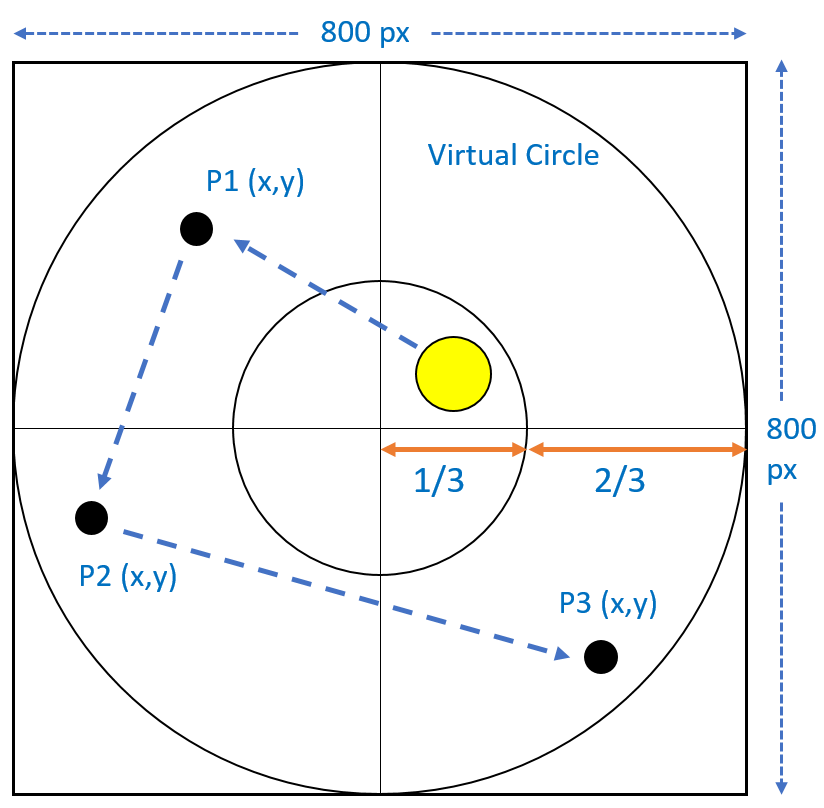
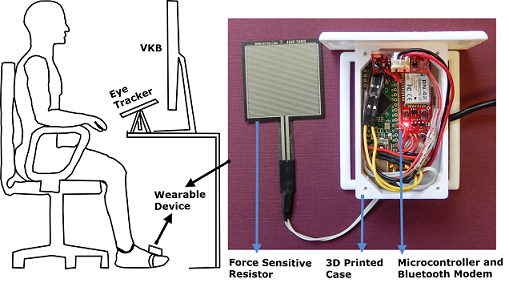
Gaze Typing Through Foot-Operated Wearable Device

Gaze-Assisted User Authentication to Counter Shoulder-surfing Attacks




GAWSCHI: Gaze-Augmented, Wearable-Supplemented Computer-Human Interaction



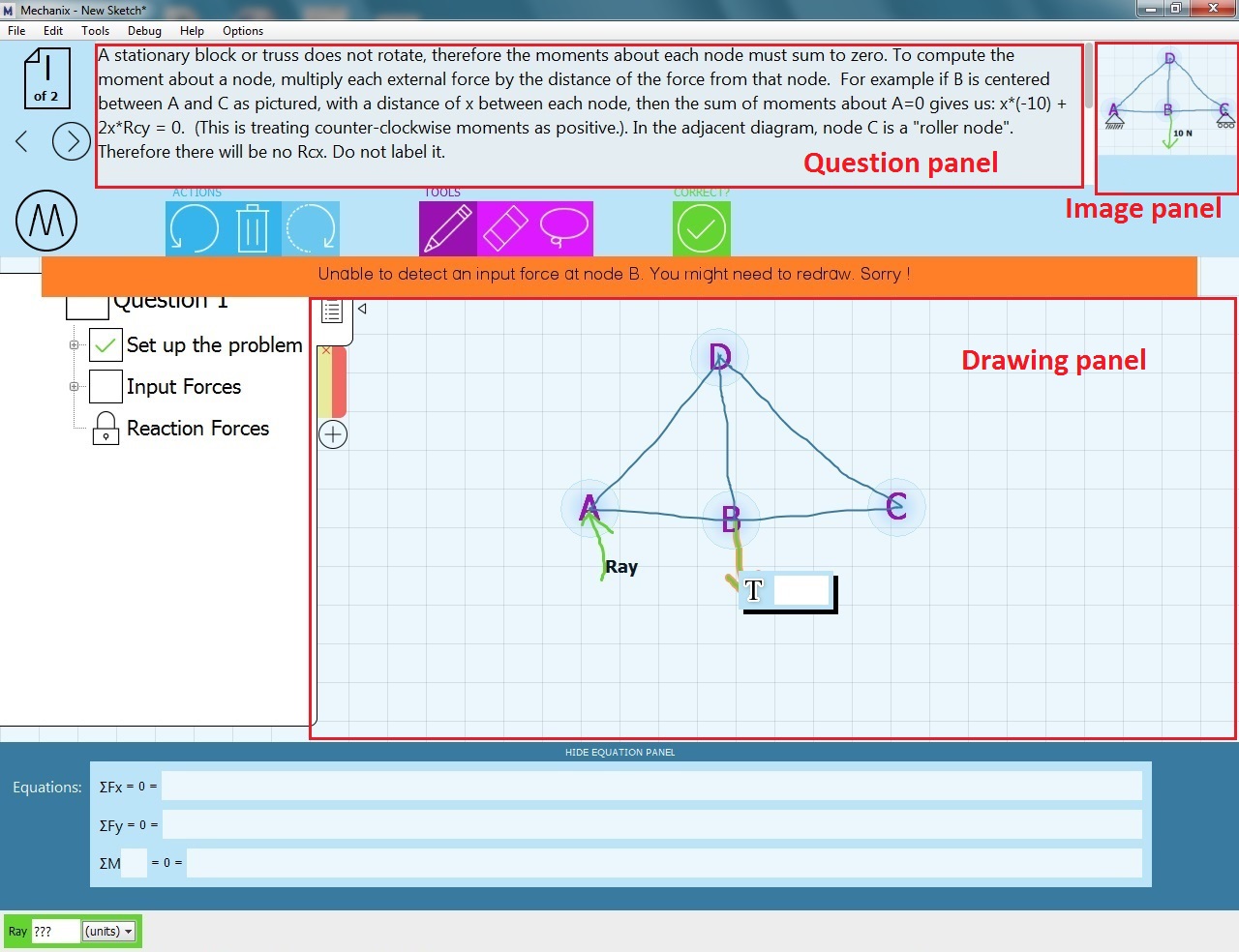
Exploring Users' Perceived Activities in a Sketch-based Intelligent Tutoring System Through Eye Movement Data
First Author: Purnendu Kaul
KinoHaptics: An Automated, Haptic Assisted, Physio-therapeutic System for Post-surgery Rehabilitation and Self-care

Objectives and Solution:
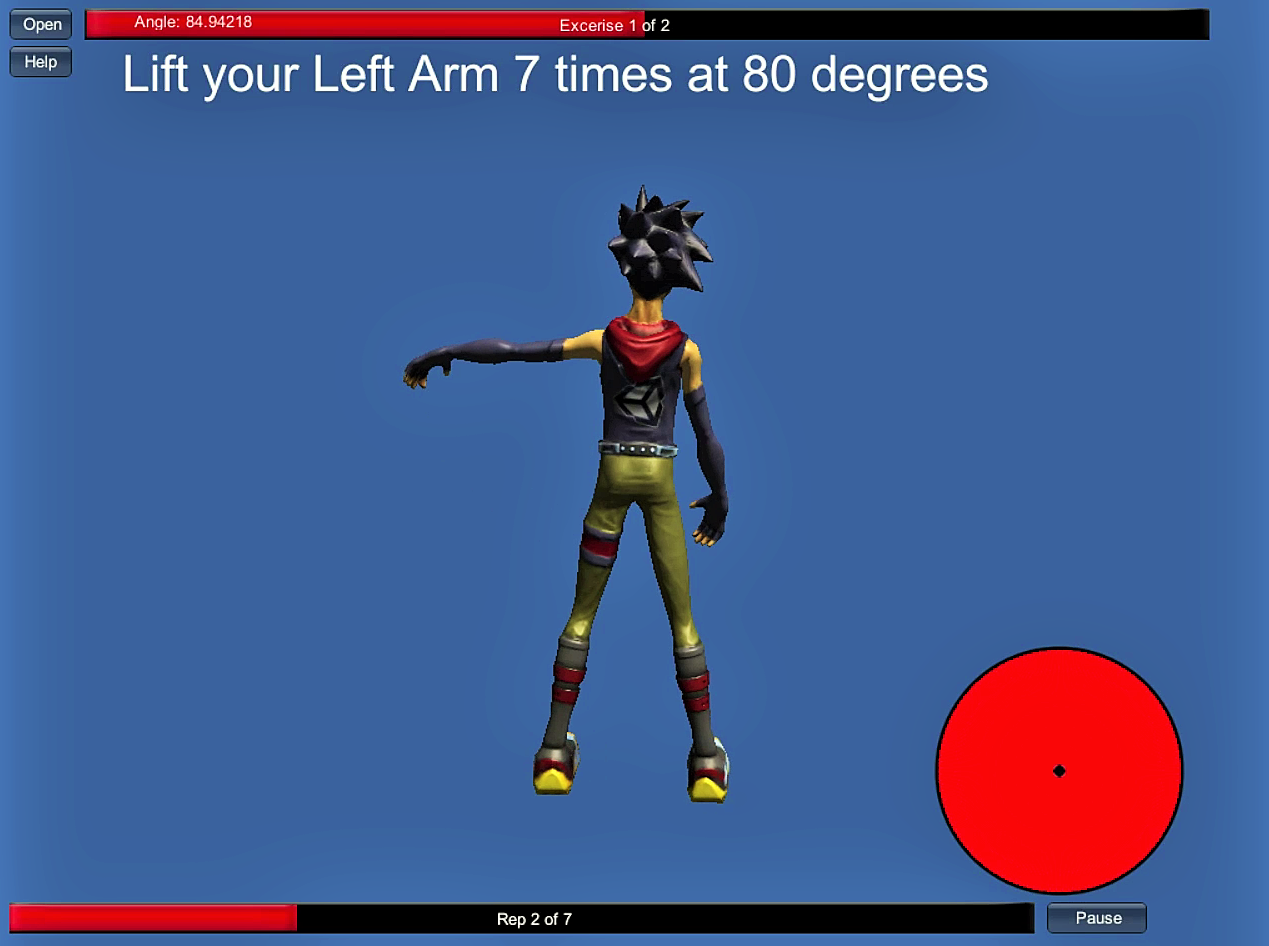
The system was evaluated under laboratory conditions, involving 14 users. Results show that KinoHaptics is highly convenient to use, and the vibro-haptic feedback is intuitive, accurate, and definitely prevents accidental injuries. Also, results show that KinoHaptics is persuasive in nature as it supports behavior change and habit building.
Conclusion:
The successful acceptance of KinoHaptics, an automated, haptic assisted, physio-therapeutic system proves the need and future scope of automated physio-therapeutic systems for self-care and behavior change. It also proves that such systems incorporated with vibro-haptic feedback encourage strong adherence to the physiotherapy program; can have a profound impact on the physiotherapy experience resulting in higher acceptance rate.
Healthy Leap: An Intelligent Context-Aware Fitness System for Alleviating Sedentary Lifestyles
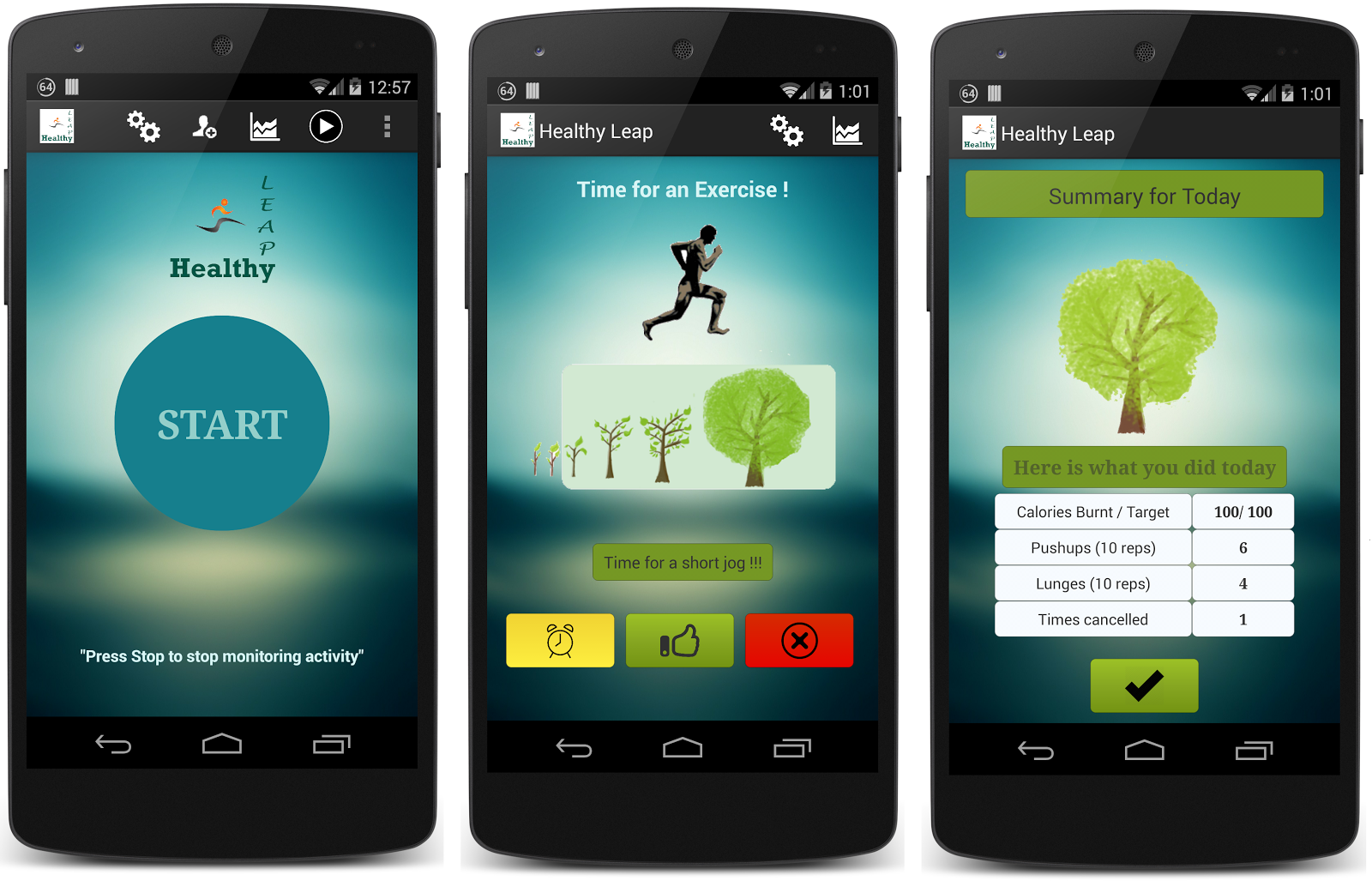
Let Me Relax: Toward Automated Sedentary State Recognition and Ubiquitous Mental Wellness Solutions


Framework for Accelerometer Based Gesture Recognition and Integration with Desktop Applications
A short distance communication protocol, Bluetooth, is used to transmit the accelerometer data from a smartphone to a desktop at a constant rate, making the whole system wireless. Accelerometer data received at the desktop computer is analyzed to identify the most appropriate gesture it encodes, and further, is transformed corresponding key press and mouse events. The key-press and mouse events thus generated control various applications and games on a desktop computer. This framework enriches interaction with desktop applications and games, and enhances user experience through intuitive and lively gestures. The framework also enables the development of more creative games and applications, which is an exciting way of being engaged.
Multi-threaded Download Accelerator With Resume Support
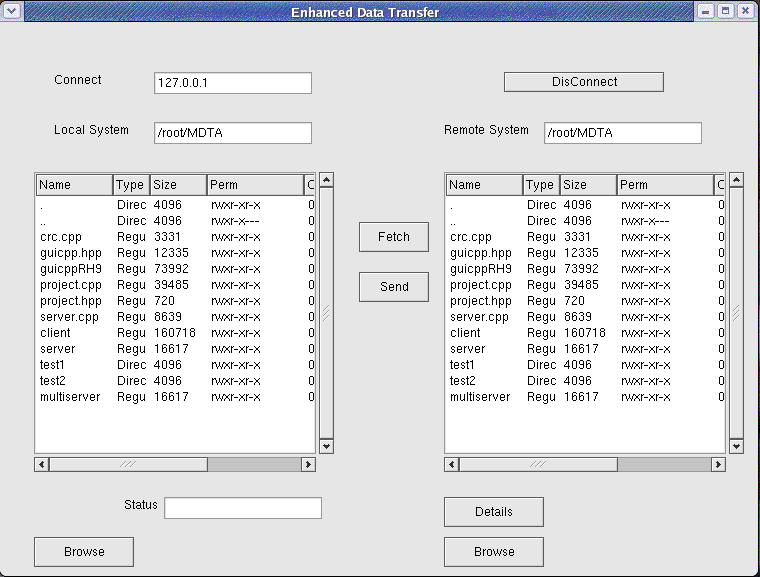
Solution:
- To develop a server that can support file transfer transactions, with resume support
- To develop a client that can provide an attractive graphical user interface to the user and help the user connect to specific systems and transfer files. Furthermore, the client must be able to maintain the status of all downloads.
- To develop a protocol that ensures that the client can communicate with the server.
- To incorporate multi-threading in order to improve bandwidth utilization, with proper communication amongst threads so that there is no synchronization problems or race conditions.
- To introduce resume support by incorporating CRC checks, so that incomplete downloads can be resumed from the point where it was left off.
Graphics Editor

Graphics Editor is mouse driven with different functions represented as icons. The GUI is user friendly, as anyone can easily use the editor without any learning prerequisites. In addition, the system provides different colors that can be applied to geometrical figures and different patterns that can be used to fill shapes (rectangle, circle).
Linux Shell

- On logging into the terminal, the custom shell displays the Linux prompt indicating that it is ready to receive a command from the user.
- The user issues a command, for example: ls <directory-name>
- The custom shell then,
- Reads the command,
- Searches for and locates the file with that name in the directories containing utilities,
- Loads the utility into memory and executes the utility.
- After the execution is complete, the shell once again displays the prompt, conveying that it is ready for the next command.
Lex Yaac

Further these "Tokens" are fed to customized implementation of "YAAC" parser that enables a user to specify "Grammar" to suit the requirements of custom interpreter.